


(following http://www.debianadmin.com/mysql-database-server-installation-and-configuration-in-ubuntu.html)
Here is the procedure how to change Mysql default data directory
By default, MySQL’s datadir is placed in the /var/lib/mysql directory.
Create the directory that will be new datadir (ex:-/home/db)
chown the directory to the mysql:mysql user
sudo chown -R mysql:mysql /home/db/*
You need to stop the mysql server using the following command
sudo /etc/init.d/mysql stop
Now you need to edit the /etc/mysql/my.cnf file
sudo vi /etc/mysql/my.cnf
and look for “datadir = /var/lib/mysql” this si where mysql database default data directory here you need to change this one to your new directory
datadir = /home/db
copy the files from the old datadir to the new location. However, make sure that the files named
ib_arch_log_0000000000, ib_logfile0 etc. are not copied to the newer location.
Make sure that the files and directories are owned by mysql user
Make changes in the my.cnf to point the new datadir.
Restart the MySQL database
sudo /etc/init.d/mysql start
----
Following: http://neodon.blogspot.com/2008/09/changing-data-directory-for-mysql-in.html
You simply edit /etc/apparmor.d/usr.sbin.mysqld. Underneath the two lines authorizing the default MySQL data directories, add two more with your custom directory. Make sure you have a trailing / on the directory name, otherwise it will not work (I had this problem at first). After this change, restart AppArmor:
sudo invoke-rc.d apparmor restart
Now you should be able to set up the new directory as a MySQL data directory and initialize it using mysql_install_db. For more information on this topic, check out the following links:
Sunday, December 28, 2008
MySQL data in /home direcotory
Thursday, December 04, 2008
Wyświetlanie Daty
strftime:
%a - The abbreviated weekday name (``Sun'')
%A - The full weekday name (``Sunday'')
%b - The abbreviated month name (``Jan'')
%B - The full month name (``January'')
%c - The preferred local date and time representation
%d - Day of the month (01..31)
%H - Hour of the day, 24-hour clock (00..23)
%I - Hour of the day, 12-hour clock (01..12)
%j - Day of the year (001..366)
%m - Month of the year (01..12)
%M - Minute of the hour (00..59)
%p - Meridian indicator (``AM'' or ``PM'')
%S - Second of the minute (00..60)
%U - Week number of the current year,
starting with the first Sunday as the first
day of the first week (00..53)
%W - Week number of the current year,
starting with the first Monday as the first
day of the first week (00..53)
%w - Day of the week (Sunday is 0, 0..6)
%x - Preferred representation for the date alone, no time
%X - Preferred representation for the time alone, no date
%y - Year without a century (00..99)
%Y - Year with century
%Z - Time zone name
%% - Literal ``%'' character
t = Time.now
t.strftime("Printed on %m/%d/%Y") #=> "Printed on 04/09/2003"
t.strftime("at %I:%M%p") #=> "at 08:56AM"
Saturday, November 22, 2008
Netbeans 6.5, a GIT
W przypadku nowej wersji Netbeansa, szczególnie dla developerów Ruby on Rails uciążliwy może być brak wsparcia dla systemu wersjonowania GIT. Na szczęście dostępny jest już odpowiedni moduł (na razie w wersji eksperymentalnej), który doda do naszego środowiska odpowiednie wsparcie. Zainteresowanych odsyłam na oficjalną stronę.
Thursday, November 20, 2008
NetBeans 6.5
Właśnie ukazał się nowy NetBeans 6.5. Od dłuższego czasu używam tego środowiska do pisania aplikacji w Ruby on Rails i śmiało mogę go polecić wszystkim, którzy szykają edytora wspirającego w "rozsądny sposób podpowiadanie składni". Bardzo ciekawą cechą podpowiedzi kodu w NetBeansie jest wyświetlanie również odpowiedniego fragmentu RDoca, co umożliwia szybki dostęp do bardzo wielu przykładów użycia danych metod (bardzo cenne zwkłaszcza dla metod ActiveResource).
Zainteresowanych odsyłam również na stronę Huukau, gdzie znajduje się bardzo dobry schemat graficzny dla developerów rubiego.
Alternatywny temat kolorystyczny znaleźć możemy również na stronie Tora Norbyesa
Na zakończenie ostatni ciekawy temat kolorystyczny, który znaleźć możemy na stronie iBrasten.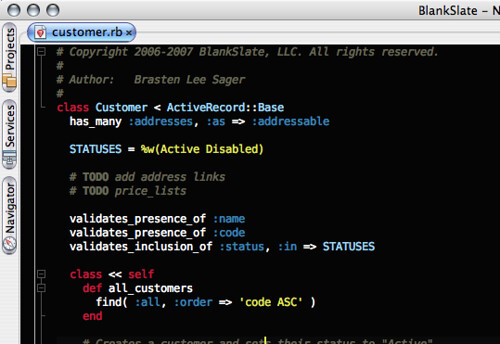
Monday, November 03, 2008
Ubuntu 8.10 Sun Java 1.6
Instalacja:
sudo apt-get install sun-java6-jdk
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/java-6-sun/jre/bin/java 1100
RubyGems 1.3.1 na Ubuntu 8.10
Wraz z pojawieniem się nowej wersji Ubuntu 8.10 - nie obeszło się bez problemów. Domyślnie dla tej wersji apt-get instaluje rubygemy w wersji 1.2. Niestety polecenie:
sudo update_rubygems
Wydane po instalacji "gem install rubygems-update" się nie wywołuje.
Oto metoda jak sobie z tym poradzić znaleziona na blogu (http://roninonrails.blogspot.com/2008/11/setting-up-ubuntu-810-for-ruby-on-rails.html):
wget http://rubyforge.org/frs/download.php/45905/rubygems-1.3.1.tgz
cd rubygems-1.3.1
ruby setup.rb
ln -s /usr/bin/gem1.8 /usr/bin/gem
Thursday, October 16, 2008
Ruby on Rails pod maską Ogólnopolskiej Informacji Medycznej
Firma Delta Software oficjalnie uruchomiła serwis Ogólnopolskiej Informacji Medycznej. Cały projekt zrealizowany został w technologii Ruby on Rails. Technologia ta umożliwiła wytworzenie produktu, który stać się ma największą konkurencją dla dotychczasowych portali medycznych. W chwili obecnej system działa w podstawowej funkcjonalności, jednakże bardzo szybko uruchamiane są dodatkowe moduły. W ostatecznej wersji serwis wykorzystywać będzie również algorytmy sztucznej inteligencji.
Thursday, July 10, 2008
Instalacja Ruby on Rails 2.1 pod Ubuntu 8.04
Informacje zaczerpnięte są ze strony "Installing Ruby & Rails on Ubuntu 8.04 Hardy Heron", ale jednocześnie starałem się je uzupełnić o rozwiązania problemów na jakie można trafić w trakcie instalacji (dodane elementy starałem się wyróżniać kolorem czerwonym).
Krok 1:
Instalacja pakietów podstawowych
sudo apt-get install ruby irb ri rdoc ruby1.8-dev
libzlib-ruby libyaml-ruby libreadline-ruby libncurses-ruby libcurses-ruby libruby
libruby-extras libfcgi-ruby1.8 build-essential libopenssl-ruby libdbm-ruby libdbi-ruby
libdbd-sqlite3-ruby sqlite3 libsqlite3-dev libsqlite3-ruby libxml-ruby libxml2-dev
ruby rubygems
Krok 2:
Instalacja najnowszej wersji gem
sudo gem update --system
Może się zdażyć, że pojawi się komunikat następującej treści:
uninitialized constant Gem::GemRunner
Rozwiązanie można znaleźć na tej stronie, ale ponieważ jest krótkie pozwoliłem sobie je zamieścić poniżej:
sudo gedit /usr/bin/gem
A następnie przed linią:
require 'rubygems'
Dodajemy:
require 'rubygems/gem_runner'
3. Krok
Dalsza aktualizacja gema:
gem install rubygems-update
sudo update_rubygems
4. Krok
Instalacja railsa
sudo gem install rails
To zainstaluje nam najnowszą wersję railsa. Gdybyśmy chcieli zainstalować również wcześniejszą wersję należy wywołać następującą komendę (zainstaluje ona railsa w wersji 2.0.2)
sudo gem install rails -v 2.0.2
5. Krok
Instalacja bazy danych i narzędzi pomocniczych
sudo apt-get install mysql-server mysql-client libdbd-mysql-ruby mysql-query-browser mysql-admin
6. Krok
Instalacja gema mysql
sudo gem install mysql
W przypadku problemów z isntalacją warto przeczytać tego posta.
6. Krok
Instalacja dodatkowych przydatnych gemow:
sudo gem install mongrel sqlite3-ruby capistrano mini_magick mislav-will_paginate
Tuesday, July 08, 2008
Instalacja gema mysql pod ubuntu
Jeżeli w czasie wywołania:
sudo gem install mysql
Pojawia się następujący błąd:
/usr/bin/ruby1.8 extconf.rb install mysql
checking for mysql_query() in -lmysqlclient... no
checking for main() in -lm... yes
checking for mysql_query() in -lmysqlclient... no
checking for main() in -lz... yes
checking for mysql_query() in -lmysqlclient... no
checking for main() in -lsocket... no
checking for mysql_query() in -lmysqlclient... no
checking for main() in -lnsl... yes
checking for mysql_query() in -lmysqlclient... no
*** extconf.rb failed ***
Należy zainstalować następującą bibliotekę:
sudo apt-get install libmysqlclient15-dev
A następnie wywołać:
sudo gem install mysql
Thursday, July 03, 2008
Drag&Drop dla drzewa
Jeżeli w projekcie nad którym pracujemy potrzebna jest funkcjonalność zapewniająca sortowanie listy możemy wykorzystać dwie rzeczy - ScriptAculoUs(domyślnie dostarczona wraz z railsem) oraz ActsAsList.
Problem stanowiło natomiast utworzenie sortowalnego drzewa. Z pomocą w tym przypadku przychodzi rozwiązanie opracowane przez Svena Fuchsa.
Poniżej przykładowe dwa dema:
demo/bold.html
demo/textmate.html
Friday, June 27, 2008
Migracje w rails 2.1
W nowym wydaniu Railsa w wersji 2.1 w nasze ręce oddana została poprawiona funkcjonalność związana z zarządzaniem migracjami. Poprawione zostały dwie rzeczy. Pierwsza dotyczy generowania samych migracji, które przestały być już oznaczane kolejnymi numerami wersji (stanowiło to czasami nie lada wyzwanie kiedy w projekcie kilka osób jednocześnie pracowało z modelem), a druga możliwości określania zmian w tabelach.
Od wersji rails 2.1 migracje numerowane są tak zwanym stemplem czasowym. W praktyce oznacza to, że wygenerowanie migracji za pomocą script/generate migration nowa_migracja spowoduje utworzenie pliku o nazwie zbliżonej do tej: 20080627102918_nowa_migracja.rb
Wcześniej jeżeli dwie osoby jednocześnie wygenerowały migracje trzeba było cofać wprowadzone zmiany (najlepiej przed pobraniem zmian z SVNa - ponieważ tylko wtedy odbywało się to w miarę bezproblemowo), zmieniać nazwy plików i dopiero wówczas migrować model. Teraz proces ten przeprowadzany jest automatycznie. W momencie w którym rake db:migrate stwierdzi, że w katalogu znajdują się migracje z wcześniejszym stemplem czasowym, cofa wszystkie zmiany, a następnie migruje model z uwzględnieniem wcześniejszej migracji.
Druga zmiana w Railsie 2.1 dotyczy sposobu w jaki możemy definiować zmiany tabel przyjrzyjmy się poniższemu fragmentowi kodu:
change_table :news do |:tabela|
tabela.belongs_to :issue # Doda kolumnę issue_id
tabela.string :naglowek, :autor # Doda dwie kolumny typu string
tabela.remove :header, :author #Usunie dwie kolumny
end
Do dyspozycji mamy teraz następujace modyfikatory dostępne w bloku kodu metody change_table:
- tabela.index - dodaje indeks
- tabela.change - zmienia definicję kolumny np. tabela.change :nazwa, :string, :limit => 200
- tabela.change_default - zmienia wartość domyślną dla kolumny
- tabela.rename - zmienia nazwę kolumny
- tabela.remove - usuwa kolumnę
- tabela.remove_belongs_to - usuwa kolumnę z kluczem obcym
- tabela.remove_timestams - stemple czasowe
- dodatkowo możemy używać (references, string, text, integer, float, decimal, datetime, timestamps, time, date, binary, boolean)
Błąd: no such file to load -- mkmf
W przypadku kiedy chcemy zainstalować Mongrela, a pojawia się nam poniższy błąd:
Building native extensions. This could take a while...
ERROR: Error installing mongrel:
ERROR: Failed to build gem native extension.
/usr/bin/ruby1.8 extconf.rb install mongrel
extconf.rb:1:in `require': no such file to load -- mkmf (LoadError)
from extconf.rb:1
należy zainstalować developerską wersję ruby
sudo apt-get install ruby1.8-dev
To powinno rozwiązać problem.
Problem z zależnościami rubygems w ubuntu 8.04
Korzystając z nowego railsa 2.1 w ubuntu 8.04 możemy natknąć się na następujący problem
/usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/locator.rb:91:in `add': wrong number of arguments (2 for 1) (ArgumentError)
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/locator.rb:91:in `plugins'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:63:in `locate_plugins'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:62:in `map'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:62:in `locate_plugins'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:27:in `all_plugins'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:22:in `plugins'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/rails/plugin/loader.rb:45:in `add_plugin_load_paths'
from /usr/lib/ruby/gems/1.8/gems/rails-2.1.0/lib/initializer.rb:235:in `add_plugin_load_paths'
Występuje on w momencie kiedy dodamy do pliku konfiguracyjnego informację wiążącą naszą aplikację z konkretnymi gemami (i to o dziwo nie wszystkimi bo will_paginate działa prawidłowo) np.:
config.gem 'mini_magick', :version => '~>1.2.3'
Googlując za rozwiązaniem udało mi się znaleźć witrynę http://rails.lighthouseapp.com/projects/8994/tickets/293-gem-dependencies-broken-in-2-1-0, gdzie z opisu w kolejnych postach można wywnioskować, że usunięcie pakietu rubygems i zainstalowanie go ze źródeł powinno pomóc. Niestety w moim przypadku nie dało to oczekiwanego rezultatu.
Thursday, June 26, 2008
Ściągawki dla programistów ruby on rails
Natknąłem się dzisiaj na bardzo ciekawy, a zarazem szeroki zbiór krótkich ściągawek dla programistów ruby on railsa.
Warte polecenia:
http://radarek.jogger.pl/2008/03/12/zestaw-ponad-40-sciagawek-dla-programistow-ruby-on-rails-i-n/
Paginacja w rails 2.1 (gem will_paginate)
W railsie 2.0.2 do paginacji można było używać will_paginate instalowanego jako plugin. Po przejściu do railsa 2.1 okazało się, że widoki zawierające paginatory przestały działać. Nie będę opisywał tutaj walki z usunięciem tego błędu - bo skutkowała wieloma mało zrozumiałymi komunikatami.
Aby wykorzystać paginacje w railsie 2.1 należy:
- usunąć katalog will_paginate z /vendor/plugins/
- do pliku environment.rb dodać nastepującą linijkę:
config.gem 'mislav-will_paginate',
:version => '~> 2.3.2',
:lib => 'will_paginate',
:source => 'http://gems.github.com'
Uwaga:na sieci znalazłem kilka wersji sposobu dodania will_paginate do environment.rb - niestety nie wszystie chciały działać! - Na końcu pliku environment.rb należy dopisać (za słowem kluczowym end):
require 'will_paginate' - wywołać task raka:
sudo rake gems:install
Uwaga: instalacja gemów wymaga uprawnień administratora
Teraz możemy cieszyć się prawidłowo działającą aplikacją.
Różnica pomiędzy count, length a size
W ruby on rails mamy do dyspozycji trzy metody określające ilość elementów w kolekcji - length, count, size. Aby zoptymalizować działanie naszej aplikacji warto jednak wiedzieć w jaki sposób działa każda z nich:
- length (np. obiekt.kolekcja.length) - pobiera całą kolekcje, a nastepnie zwraca liczbę elementów
- count (np. obiekt.kolekcja.count) - zwraca liczbę elementów nie pobierając kolekcji do pamięci (wykorzystuje SQLową instrukcję count)
- size (np. obiekt.kolekcja.size) - metoda ta jest połączeniem działania dwóch poprzednich metod. Jeżeli obiekt.kolekcja został wcześniej pobrany to działanie jest podobne do instrukcji length, jeżeli natomiast kolekcja nie została pobrana wywołana zostanie instrukcja count
Mam nadzieję, że to krótkie wyjaśnienie pozwoli zrozumieć różnicę pomiędzy tymi trzema instrukcjami i jednocześnie pozwoli tworzyć bardziej efektywny kod.
Tuesday, June 24, 2008
Programowanie gier, modyfikacje alfa-beta obcięcia oraz heurystyki funkcji oceniających.
Pełna wersja dokumentu dostępna pod adresem: http://www.deltasoftware.pl/dokumenty/Michal_Stanek-Sztuczna_inteligencja_w_grach.pdf
Wstęp
Gwałtowny rozwój komputerów w drugiej połowie ubiegłego wieku przyczynił się do znacznego postępu zarówno w nauce jak i przemyśle. Dały one możliwość realizacji rzeczy które wcześniej można było analizować jedynie teoretycznie. W głowie nie jednego naukowca zrodziło się wówczas pytanie, czy maszyna będzie w stanie dorównać kiedyś możliwością człowieka?
Zaczęła rozwijać się dynamicznie dziedzina zwana sztuczną inteligencją. Zadawano sobie pytanie w jaki sposób mierzyć zdolności maszyny? Dylemat ten rozwiązał Alan Turing konstruując słynny test Turinga. Test ten odnosi się jednak tylko do zdolności językowych. Sam Alan Turing a nawet Shannon rozważał rozszerzenie tego testu o przeprowadzenie rozgrywki w szachy, od wieków bowiem gra ta była uznawana za królową wszystkich gier. Turing stwierdził nawet w jednej ze swoich wypowiedzi z 1951 roku, że nikt nie jest w stanie napisać programu, który gra lepiej od niego samego. Mimo niezaprzeczalnie wielkiego geniuszu w tej kwestii się pomylił.
Mimo że nie ujęta w teście Turinga gra w szachy przez wielu uważana była za wyznacznik zdolności maszyny do myślenia. Określała granicę pomiędzy możliwościami ludzkiego umysłu a maszyną. Ostatecznie po 45 latach prób, zaczynając od roku 1952, kiedy to powstał pierwszy program A. Sammuela, maszyna pokonała szachowego mistrza świata.
Nie tylko szachy wzbudzały zainteresowanie uczonych. Badania i eksperymenty prowadzone były dla bardzo wielu popularnych gier, wśród nich othello, go warcaby. W wielu z nich ostateczny sukces, to znaczy zwycięstwo nad człowiekiem został osiągnięty dużo wcześniej niż w szachach. Przykładowo problem gry w warcaby uważa się obecnie za praktycznie rozstrzygnięty. Oznacza to, że w zdecydowanej większości przypadków jesteśmy w stanie określić wynik gry już po wykonaniu kilku pierwszych ruchów.
Gra, strategia i drzewo gry
Według definicji Von Noumana i Morgensterna gra to składa się z zestawu reguł określających możliwości wyboru postępowania jednostek znajdujących się w sytuacji określanej mianem konfliktu interesów. Każda z tych jednostek stara się maksymalizować swój własny zysk i jednocześnie zminimalizować zysk pozostałych graczy. Reguły gry określają też ilość informacji dostępną każdemu z graczy oraz wysokość wygranych i przegranych.
W ogólności grę można rozumieć jako rozgrywkę prowadzoną przez gracza lub graczy, zgodnie z ustalonymi zasadami gry, w celu osiągnięcia ściśle zdefiniowanego celu.
Należałoby również zdefiniować pojęcie równie ważne - strategia gry, pod którym rozumieć będziemy kompletny zbiór zasad, które determinują posunięcia gracza, wybierane zależnie od sytuacji powstających podczas gry.
Gry można podzielić również na kilka kategorii w zależności od charakterystycznych cech.
Ze względu na ilość graczy:
- Gry bezosobowe (np. Gra w życie)
- Gry jednoosobowe (puzzle, pasjans)
- Gry dwuosobowe (szachy, warcaby, otello, go)
- Gry wieloosobowe (poker, brydż)
Wygrana i przegrana:
- Gry o sumie zerowej (wygrana jednego gracza oznacza przegraną drugiego gracza) – szachy, warcaby, otello
- Gry o sumie nie zerowej – np. Dylemat więźnia
Współpraca graczy:
- Kooperacyjne (gracze współpracują ze sobą)
- Niekooperacyjne (gracze nie współpracują ze sobą)
Występowanie w grze elementu losowości:
- ałkowicie losowe (ruletka)
- Częściowo losowe (brydż i inne gry karciane)
- Całkowicie deterministyczne (warcaby, szachy, otello, go)
To czym jest gra można wyrazić również pewnym równaniem:
Gra = cel + stan początkowy + operatory
Gdzie pod pojęciem operatora rozumieć możemy stosowanie reguł gry. Działanie operatora nie musi być deterministyczne – może go określać np. rozkład zmiennej losowej, w grach częściowo losowych takich np. brydż. Każdy operator może posiadać również koszt związany z jego zastosowaniem. Należy podkreślić, że w grze dwuosobowej mamy wpływ na wybór tylko połowy operatorów.
Rozpoczęcie gry ze stanu początkowego, a następnie stosowanie możliwych operatorów prowadzi do zbudowania tak zwanego drzewa gry, którego reprezentacja przedstawiona jest na rysunku 1(rysunek dostępny w dokumencie pdf).
Algorytm Min-Max
Jednym z większych osiągnięć w teorii gier było opracowanie algorytmu min-max[KNU75]. Zasada jego działania opiera się na prostym spostrzeżeniu, że podczas gry każda ze stron stara się maksymalizować swoje zyski, przy jednoczesnej minimalizacji zysków przeciwnika1(podejście takie można zauważyć już w definicji Von Noumana i Morgensterna).
Zakładając że możemy oszacować stan gry w każdym momencie z dość dużym przybliżeniem, jesteśmy w stanie przewidzieć, które ruchy przybliżą nas do wygranej, a które nie. Oczywiście im głębiej będziemy analizować drzewo gry, tym lepiej można wybrać operatory, które prowadzą nas do wygranej. W ekstremalnym przypadku, gdy jesteśmy w stanie rozwinąć całe drzewo gry jednoznacznie możemy wybrać posunięcia prowadzące nas do wygranej. Algorytm min-max został opracowany i opublikowany przez Knutha i Moore'a w 1975 r. Stanowi on fundament działania wielu innych algorytmów. Ilustracja działania algorytmu min-max przedstawiona jest na rysunku 2 (dostępny w wersji pdf dokumentu).
Na jakość gry przy wykorzystaniu algorytmu min-max wpływają z jednej strony głębokość przeszukiwania z drugiej jakość funkcji heurystycznej. Nie da się osiągnąć zadowalających wyników jeżeli którykolwiek z tych elementów jest źle dobrany.
Algorytm min-max przyczynił się do powstania algorytmu alfa-beta obcięcia, którego działanie polega na ograniczeniu ilości rozwijanych wierzchołków drzewa gry. Dokładne opisy algorytmu Alfa-Beta obcięcia można znaleźć w pracy [KWA04].
Konstrukcja funkcji heurystycznej
Jak wspomniano we wcześniejszym rozdziale na jakość działania algorytmy alfa-beta obcięcia zasadniczy wpływ ma stworzenie odpowiedniej funkcji oceniającej. Funkcja oceniająca jest funkcją heurystyczną1, to znaczy konstruowaną w założeniu, że pewne stany gry są lepsze lub gorsze od innych. Funkcja heurystyczna zazwyczaj przyjmuje postać wielomianu postaci:
F(s) = w1 * x1 + ... + wn * xn,
gdzie:
s - to pewien stan gry, który chcemy ocenić,
x1 - do xn to pewne cechy (np. ilość pionków na planszy, zajmowanie pewnych pól szachownicy),
w1 - do wn są wagami z jakimi brana jest pod uwagę wartość pewnej cechy.
Konstrukcja funkcji heurystycznej, to znaczy dobór odpowiednich parametrów oraz ich wag, zależy zazwyczaj od projektanta (programisty). Z jednej strony podejście takie jest dobre, ponieważ pozwala podzielić problem na dwa mniejsze:
- wyboru cech branych pod uwagę,
- doboru wagi każdej z wcześniej wybranych cech.
Z drugiej natomiast pozostawia pewien element subiektywności osobie, która konstruuje taką funkcję.
GLEM – ogólny liniowy model oceniania
W odpowiedzi na problemy związane z konstrukcją heurystycznych funkcji oceniających powstał GLEM (Generalized Linear Evaluation Model). Ideą jaka przyświecała jego powstaniu była chęć stworzenia standardowego sposobu rozwiązywania klasy problemów cechujących się tym, że funkcję heurystyczną można przedstawić jako kombinację liniową dostatecznej ilości cech [BURO02]. GLEM nie zwalnia nas co prawda z obowiązku wyboru cech podstawowych, przez autorów artykułu nazwanych atomowymi. Nadal zmuszeni jesteśmy określić jakie elementy mają być brane pod uwagę. Przez cechy atomowe rozumiemy tutaj na przykład cechy takie jak obecność konkretnego pionka na konkretnym polu planszy, posiadanie konkretnej karty itp. Resztę parametrów to znaczy wartości wag z jakimi cechy te będą brane pod uwagę dobierane są przez algorytm automatycznie na podstawie dostarczonych przykładów uczących.
.... dalsza część artykułu dostępna w wersji PDF
Wzorce projektowe warsty prezentacji
Dokument w wersji PDF można pobrać z tego miejsca http://www.deltasoftware.pl/dokumenty/Michal_Stanek-Wzorce_Projektowe.pdf
Wstęp
Wzorce projektowe są ogólnymi rozwiązaniami popularnych problemów, jakie pojawiają się podczas projektowania systemów informatycznych. Użycie przetestowanych i efektywnych rozwiązań pozwala zminimalizować koszty oraz skrócić czas potrzebny do wytworzenia oprogramowania. Polepszeniu ulega także komunikacja między ekspertami i zespołami projektowymi.
Dokument ten omawia wzorce projektowe warstwy prezentacji, na przykładzie platformy J2EE. Po wstępnym omówieniu problemów związanych z tworzeniem nowoczesnych aplikacji biznesu elektronicznego, przedstawione zostały trzy wzorce projektowe warstwy prezentacji: Intercepting Filter, Context Object, Composite View. Każdy wzorzec został ogólnie omówiony, przedstawiono diagramy klas oraz sekwencji, przedstawiono również przykładowe strategie implementacji.
Projektowanie aplikacji J2EE
Specyfikacja J2EE powstała z myślą o zaspokojeniu potrzeb developerów aplikacji biznesu elektronicznego. Zawiera ona takie składowe jak strony JSP, komponenty JSP, usługi nazw jak JNDI, i wiele innych. Każdy z tych składników w mniejszym lub większym stopniu zaspokaja potrzeby
- EJB - Reprezentuje komponent Enterprise Java Bean, związany jest z reguły z obiektem biznesowym. Rolę tę pełni zazwyczaj komponent sesyjny lub Entity.
- JSP - Java Server Pages. Technologia związana z generowanie widoku za pomocą osadzenia kody Javy na stronie HTML. Kod Javy zawarty jest w specjalnych znacznikach, a sama strona JSP wykonywana jest przez serwer servletów.
Trzeba zdawać sobie sprawę z tego, że wiele, a można byłoby zaryzykować twierdzenie, że większość dzisiejszych aplikacji biznesu elektronicznego wykorzystuje możliwości, jakie dają sieci komputerowe. Projektanci stają wobec tego przed zupełnie nowymi wyzwaniami, wśród których wyróżnić można aspekt związany z rozproszeniem, dostępnością, bezpieczeństwem itp. Tym własnie wyzwanią stawiają czoła wzorce projektowe opracowane dla platformy J2EE przez konsorcjum Sun Java Center. Niniejszy dokument skupi sie na omówieniu trzech wzorców warstwy prezentacji.
Wzorce projektowe w J2EE
Wzorce projektowe są ogólnymi rozwiązaniami popularnych problemów, jakie pojawiają się podczas projektowania systemów informatycznych. Użycie przetestowanych i efektywnych rozwiązań pozwala w efekcie uzyskać lepsze rozwiązania charakteryzujące się miedzy innymi:
- Poprawionym aspektem przyszłej pielęgnacji aplikacji.
- Lepszą modułowością.
- Możliwością rozdzielenia ról członków zespołu projektowo-programistycznego.
- Poprawieniem bezpieczeństwa dostępu.
- Redukcją intensywności komunikacji sieciowej.
- Zminimalizowanym kosztem wytworzenia.
Wielokrotnym wykorzystaniem komponentów.
Podczas projektowania systemów J2EE, często napotykamy podobne problemy. Warto przyjrzeć się kilku z nim, aby zrozumieć jak wielką rolę odgrywają dzisiaj wzorce projektowe.
Często zdarza się, że niedoświadczony programista zawiera na stronie JSP kod odpowiedzialny za wygląd (HTML), logikę biznesową(Java) oraz dostęp do bazy danych(SQL). Wprowadzenie modułu sterującego pozwoliłoby uzyskać rozwiązanie zdecydowanie lepsze. Poprawiona zostałaby modułowość, jak również przyszła możliwość modyfikacji tak utworzonego kodu.
.jpg)
Równie istotnym zagadnieniem jest wydzielenie kodu odpowiedzialnego za logikę biznesową z elementu odpowiedzialnego za przygotowanie widoku. Ponieważ strony JSP pozwalają umieszczać w ich wnętrzu kod Javy, programiści bardzo często umieszczają w nich typowe akcje związane z logiką biznesową. Są one niezależne i niezwiązane z formą ich prezentacji i powinny zostać wydzielone do oddzielnych klas np. Enterprise JavaBeans.
Podobnym problemem związanym ze stronami JSP, jest umieszczenie w nich kodu odpowiedzialnego za przygotowanie oraz konwersję danych. Stwarza to kłopoty związane z redundancją kodu. Rozwiązaniem tego problemu, tak jak poprzednio jest wydzielenie kodu konwersji do oddzielnych klas.
.jpg)
Programiści aplikacji internetowych napotykają również często na dwa inne problemy. Pierwszy z nich związany jest z odpowiednim ukrywaniem zasobów przed klientem, który najpierw powinien spełnić pewne warunki, np. przejść poprawnie proces logowania do systemu.
.jpg)
Drugi problem związany jest ze specyfikacją protokołu http, a dokładniej ze sposobem komunikacji przeglądarki z serwerem. Często zdarza się, że żądanie wykonania pewnej akcji zostaje powielone. W przypadku kiedy taka akcja powoduje modyfikacje danych, należy wyeliminować takie żądanie. Rozwiązaniem tych problemów może być wprowadzenie modułu sterującego takiego jak front controller [ALUR2004].
.jpg)
Doświadczony programista zdaje sobie również sprawę z faktu, że uzależnienie aplikacji od protokołu, w jakim pracuje, znacznie ogranicza jej późniejszy rozwój. W obecnych czasach, wraz z bardzo dynamicznych rozwojem urządzeń mobilnych jest to szczególnie istotne, aby aplikacja mogła pracować w wielu różnych środowiskach, a komunikacja z nią byłą możliwa za pomocą dowolnej ilości protokołów. Wzorzec projektowy o nazwie Context Object, stanowi rozwiązanie tego problemu.
.jpg)
Jest to tylko kilka problemów, z jakimi możemy spotkać się projektując aplikację sieci WWW pracującą nie tylko w technologii J2EE. Warto zaznajomić się jednak ze wszystkimi wzorcami projektowymi, gdyż wielu przypadkach nie musimy wynajdywać tak zwanego "koła" od nowa, a wypracowane przez społeczność programistów rozwiązania wielokrotnie zaspokajają wszystkie nasze potrzeby. W kolejnej części tego dokumentu omówię dokładniej trzy spośród wielu istniejących wzorców.
Wzorce projektowe J2EE warstwy prezentacji
Intercepting Filter
Często możemy spotkać się z sytuacją, w której przed przystąpieniem do właściwego przetwarzania żądania strony JSP, musimy wstępnie przetworzyć dane. Operacja ta może być przykładowo związana z przetworzeniem kodowania parametrów żądania klienta. Nie trudno sobie wyobrazić, że taka konwersja musi się pojawić na każdej stronie, która w jakikolwiek sposób wykorzystuje parametry żądania klienta. Interesuje nas wobec tego rozwiązanie, którego nie będzie trzeba integrować z głównym przetwarzaniem. Wzorzec Intercepting Filter powinniśmy stosować właśnie wtedy, gdy chcemy przechwycić i modyfikować żądanie i odpowiedź przed i po właściwym przetwarzaniu. Ogólny schemat ideowy tego rozwiązania znajduje się na poniższym rysunku:
.jpg)
Intercepting Filter najczęściej stosowany jest do:
- Sprawdzenie, czy z klientem związana jest poprawna sesja.
- Sprawdzenie, czy obsługiwany jest dany rodzaj przeglądarki.
- Sprawdzenie, jakiego kodowania używa klient do wysyłania danych oraz konwersja tych danych.
- Deszyfrowanie lub dekompresja strumienia danych.Sprawdzenie, czy z klientem związana jest poprawna sesja.
- Sprawdzenie, czy obsługiwany jest dany rodzaj przeglądarki.
- Sprawdzenie, jakiego kodowania używa klient do wysyłania danych oraz konwersja tych danych.
- Deszyfrowanie lub dekompresja strumienia danych.
Typowym rozwiązaniem tego typu problemów jest umieszczenie szeregu zagnieżdżonych instrukcji if-then-else. Ponieważ jednak kod taki trzeba umieścić w każdym elemencie naszej aplikacji uzyskujemy bardzo dużą redundancję kodu. Naszym celem jest więc zastosowanie rozwiązania charakteryzującego się następującymi właściwościami.
- Będzie stanowić scentralizowane, wspólne przetwarzanie dla wszystkich żądań (np. sprawdzanie kodowania).
- Nie będzie mocno związane z kodem przetwarzania zasadniczego.
- Będzie umożliwiać stosowanie niezależnych komponentów, które w łątwy sposób mogą być dodawane przed lub po zasadniczym przetwarzaniu.
Na dwóch poniższych rysunkach przedstawione zostały diagramy klas oraz diagramy sekwencji wzorca Intercepting Filter.
.jpg)
.jpg)
Opis poszczególnych elementów wzorca:
- FilterManager - jest menadżerem filtrów. Jego zadaniem jest tworzenie obiektu FilterChain oraz ustawienie odpowiedniej sekwencji wywoływanych filtrów. FilterManager może być konfigurowalny za pomocą zewnętrznego pliku konfiguracyjnego, który określa w jakiej kolejności i jakie filtry zostaną wywołane.
- FilterChain - stanowi uporządkowany zbiór niezależnych od siebie filtrów. FilterChain odpowiedzialny jest również za koordynowanie wywołań poszczególnych filtrów.
- Filter - reprezentuje niezależny filtr.
- Target - stanowi zasób żądania.
Najczęstszą implementacją wzorca Intercepting Filter jest wykorzystanie strategii filtru standardowego [ALUR2004]. Strategia ta zakłada wykorzystanie standardowego mechanizmu tworzenia łańcuchów filtrów, zdefiniowanego w specyfikacji serwletów w wersji 2.3. Filtry tak utworzone bazują na standardowym interfejsie javax.servlet.Filter i są luźno powiązane ze sobą oraz docelowymi zasobami. Kontrola tak utworzonych filtrów odbywa się w sposób deklaratywny, za pomocą deskryptora wdrożenia.
Zastosowanie takiego podejścia pozawala nam uzyskać rozwiązanie uniwersalne, w którym każdy filtr stanowi niezależny komponent. W przyszłości istnieje możliwość ponownego wykorzystania tak przygotowanych filtrów, lub też użycia filtrów dostarczonych przez innych. Deklaratywny sposób zarządzania filtrami za pomocą deskryptora wdrożenia umożliwia napisanie aplikacji, która nieświadoma jest obecności filtrów. W żaden sposób nie są one, ani zarządzanie nimi związane z zasadniczym kodem przetwarzania. Jako przykład takiego rozwiązania przedstawię filtr, zajmujący się konwersją kodowania różnego rodzaju kodowań formularzy stron WWW. Przedstawiany kod będzie przykładem wykorzystania wzorca Intercepting Filter do implementacji wzorca o nazwie Łańcuch odpowiedzialności. Struktura klas przykładu przedstawiona jest na poniższym rysunku.
.jpg) Interceptring Filter - strategia filtru standardowego
Interceptring Filter - strategia filtru standardowegoKlasa bazowa implementująca podstawowe metody klasy Filter, z niej będą dziedziczyć klasy StandardEncodeFilter - zajmująca się przetwarzaniem formularzy standardowych (application/x-www-form-urlencoded) oraz klasa MultipartEncodeFilter - zajmująca się przetwarzaniem formularzy umożliwiających wysyłanie plików
public class BaseEncodeFilter implements javax.servlet.Filter {
private javax.servlet.FilterConfig myFilterConfig;
public void doFilter(javax.servlet.ServletRequest servletRequest,
javax.servlet.ServletResponse servletResponse,
javax.servlet.FilterChain filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
filterChain.doFilter(servletRequest, servletResponse);
}
public javax.servlet.FilterConfig getFilterConfig() {
return myFilterConfig;
}
public void destroy() { }
public void init(javax.servlet.FilterConfig filterConfig)
throws javax.servlet.ServletException {
myFilterConfig = filterConfig;
}
}
Klasa odpowiedzialna za przetwarzanie formularzy standardowych:
public class StandardEncodeFilter extends BaseEncodeFilter {
// Tworzy nowy StandardEncodeFilter
public StandardEncodeFilter() { }
public void doFilter(javax.servlet.ServletRequest servletRequest,
javax.servlet.ServletResponse servletResponse,
javax.servlet.FilterChain filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
String contentType = servletRequest.getContentType();
if ((contentType == null) || contentType.equalsIgnoreCase(
"application/x-www-form-urlencoded")) {
translateParamsToAttributes(servletRequest, servletResponse);
}
filterChain.doFilter(servletRequest, servletResponse);
}
private void translateParamsToAttributes(ServletRequest request,
ServletResponse response) {
Enumeration paramNames = request.getParameterNames();
while (paramNames.hasMoreElements()) {
String paramName = (String) paramNames.nextElement();
String [] values;
values = request.getParameterValues(paramName);
if (values.length == 1)
request.setAttribute(paramName, values[0]);
else
request.setAttribute(paramName, values);
}
}
}
Klasa odpowiedzialna za przetwarzanie formularzy umożliwiających wysyłanie plików:
public class MultipartEncodeFilter extends BaseEncodeFilter {
public MultipartEncodeFilter() { }
public void doFilter(javax.servlet.ServletRequest servletRequest,
javax.servlet.ServletResponse servletResponse,
javax.servlet.FilterChain filterChain)
throws java.io.IOException,
javax.servlet.ServletException {
String contentType = servletRequest.getContentType();
// Stosujemy filtr tylko dla kodowania wieloczęściowego
if (contentType.startsWith("multipart/form-data")){
try {
String uploadFolder = getFilterConfig().getInitParameter("UploadFolder");
if (uploadFolder == null) uploadFolder = ".";
MultipartRequest multi = new MultipartRequest(servletRequest,
uploadFolder,1 * 1024 * 1024 );
Enumeration params = multi.getParameterNames();
while (params.hasMoreElements()) {
String name = (String)params.nextElement();
String value = multi.getParameter(name);
servletRequest.setAttribute(name, value);
}
Enumeration files = multi.getFileNames();
while (files.hasMoreElements()) {
String name = (String)files.nextElement();
String filename = multi.getFilesystemName(name);
String type = multi.getContentType(name);
File f = multi.getFile(name);
// W tym miejscu w razie konieczności wykonujemy coś na pliku
}
} catch (IOException e) {
LogManager.logMessage("błąd odczytu lub zapisu pliku "+ e);
}
} // koniec if
filterChain.doFilter(servletRequest, servletResponse);
} // koniec metody doFilter()
}
Deskryptor wdrożenia konfigurujący zestaw filtrów:
StandardEncodeFilter
StandardEncodeFilter
encodefilter.StandardEncodeFilter
MultipartEncodeFilter
MultipartEncodeFilter
encodefilter.MultipartEncodeFilter
UploadFolder
/home/files
StandardEncodeFilter
/EncodeTestServlet
MultipartEncodeFilter
/EncodeTestServlet
Oprócz strategii filtru standardowego w literaturze [ALUR2004,Crawford] spotyka się również rozwiązania bazujące na własnej implementacji klasy FilterManager oraz klasy FilterChain. Nie są one jednak tak uniwersalne i przenośne jak przedstawiona strategia filtru standardowego, dlatego nie zostaną przeze mnie omówione.
Podsumowanie wzorca
Wykorzystanie wzorca Intercepting Filter wiąże się z pewnymi aspektami, z których projektant musi zdawać sobie sprawę. Jak zawsze są pozytywne oraz negatywne strony wykorzystania pewnych rozwiązań.
- Centralizacja sterowania przy użyciu niezależnych od siebie procedur obsługi (np. autoryzacja, logowanie, szyfrowanie)
- Poprawa wielokrotnego użycia
- Deklaratywna i elastyczna konfiguracja
Złe strony wzorca Intercepting Filter
- Mało wydajna wymiana danych pomiędzy filtrami
Context Object
Pisząc aplikacje często zdarza się, że wiążemy ją bardzo mocno z protokołem, w jakim pracuje. Bardzo częste są sytuacje, że w ramach całego programu wykorzystujemy obiekty HttpServletRequest. Poza brakiem możliwości zmiany protokołu komunikacyjnego takiego systemu, pojawia się bardzo duży problem z testowanie takiej aplikacji.
Należy używać wzorca Context Object w celu hermetyzacji stanu w sposób niezależny od protokołu i udostępniania go kolejnym elementom aplikacji. Trzy poniższe rysunki przedstawiają diagram klas i sekwencji wzorca.
.jpg) Context Object diagram klas
Context Object diagram klas.jpg) Context Object dla protokołu HTTP
Context Object dla protokołu HTTP.jpg) Context Object diagram sekwencji
Context Object diagram sekwencjiNajczęstszą strategią implementacji wzorca Context Objet jest strategia kontekstu żądania w postaci mapy. Stan żądania jest przekształcany do postaci standardowej implementacji interfejsu Map, która jest przekazywana dalej. Zaletą tego rozwiązania jest jego prostota. Niestety jest też ujemna strona tego rozwiązania, a wiąże się ona ze słabym typowaniem parametrów przechowywanych w mapie, które są zrzutowanie na bazową klase Object. Poniżej przedstawiona jest przykładowa implementacja:
public class FrontController extends HttpServlet {
...
private void processRequest(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, java.io.IOException {
// tworzenie obiektu RequestContext przy użyciu strategii mapy
Map requestContextMap = new HashMap(request.getParameterMap());
Dispatcher dispatcher = new Dispatcher(request, response);
requestContextMap.put("dispatcher", dispatcher);
// utworzenie instancji ApplicationController
ApplicationController applicationController = new ApplicationControllerImpl();
// przetwarzanie żądania
ResponseContext responseContext =
applicationController.handleRequest(requestContextMap);
// przetwarzanie odpowiedzi
applicationController.HandleResponse(requestContextMap,responseContext);
}
...
}
Podsumowanie
Dobre strony wzorca \textsl{Context Object}:
- Ułatwia pielęgnację i umożliwia ponowne wykorzystanie.
- Ułatwia testowanie - ze względu na wykorzystanie standardowych obiektów Javy możliwe jest testowanie aplikacji za pomocą standardowych narzędzi takich jak JUnit.
- Zmniejszone ograniczenia związane ze zmianą interfejsów.
Złe strony:
- Zmniejszona wydajność.
Composite View
Tworzenie złożonych wizualnie stron internetowych jest skomplikowaną sprawą. W przypadku kiedy tworzymy całe serwisy, wiele stron jest do siebie podobnych, lub nawet zawiera te same elementy (fragmenty szaty graficznej, system menu, itp.). Wstawianie ich na każdą stronę z osobna sprawia, że późniejsza modyfikacja tych elementów jest niezwykle pracochłonna, lub też czasami nawet nie możliwa.
Zastosowanie wzorca Composite View umożliwia konstruowanie dokumentów stron WWW poprzez złożenie elementów składowych, np. na podstawie szablonu wyglądu. Umożliwia on wprowadzenie wspólnych nagłówków, stopek, paneli nawigacyjnych w wielu miejscach dowolnego z generowanych dokumentów. W rozwiązaniach bazujących na tym wzorcu układ dokumentu wynikowego może być konfigurowany niezależnie od prezentowanej zawartości.
Composite View umożliwia również stworzenie rozwiązania w którym w prosty sposób możemy dostosować prezentowaną informację do roli użytkownika (np. kupujący, sprzedający, administrator systemu) aktualnie przeglądającego serwis WWW. Rysunek poniżej przedstawia standardową budowę strony WWW na przykładzie serwisu www.e-informatyka.pl.
.jpg) Przykładowa struktura strony WWW
Przykładowa struktura strony WWWPoniżej wypunktowane są kluczowe czynniki, które powinniśmy rozpatrzyć w celu podjęcia decyzji o zastosowaniu wzorca Composite View:
- Potrzeba zastosowania wspólnych podwidoków (nagłówków, stopek, tabel), używanych w wielu miejscach.
- Częsta konieczność zmiany wspólnych elementów wielu widoków (np. szaty graficznej).
- Chęć uniknięcia powielania elementów, oraz modułowa budowa strony widoku.
Rysunek poniżej przedstawia diagram klas wzorca Composite View.
.jpg) Composite View diagram klas
Composite View diagram klasOpis poszczególnych elementów wzorca:
- Client - wybiera widok.
- View - reprezentuje wyświetlaną stronę. Każdy obiekt View, może być obiektem typu \textsl{SimpleView} albo CompositeView.
- SimpleView - reprezentuje podstawowy element składowy widoku złożonego. Nazywany jest też podwidokiem lub segmentem widoku.
- CompositeView - składa się z kilku obiektów typu \textsl{View}.
- Template - reprezentuje szablon widoku.
- ViewManager - używa obiektu \textit{Template} do utworzenia rozkładu strony, w której osadzona jest następnie odpowiednia zawartość. Umożliwia on niezależne zarządzanie zawartością i układem strony.
.jpg) Composite View diagram sekwencji
Composite View diagram sekwencjiIstnieje kilka strategii implementacji wzorca Composite View na platformie J2EE. Do najczęściej wykorzystywanych należą strategie zarządzania widokiem za pomocą:
- komponentów Java Beans,
- znaczników standardowych,
- znaczników własnych,
- przekształceń (np. XML + XSTL).
W strategii wykorzystującej pierwszej, komponenty Java Beans odpowiadają za generowanie poszczególnych widoków. Przykład strony wykorzystującej to rozwiązanie znajduje się poniżej.
<%@ taglib prefix="c" uri="http://java.sun.com/jstl/core" %>
<%@ taglib uri="/web-INF/corej2eetaglibrary.tld" prefix="cjp" %>
<jsp:useBean id="contentFeeder"
class="javabean.ContentFeeder" scope="request" />
<table valign="top" cellpadding="30%" width="100%">
<cjp:personalizer interest='global'>
<tr>
<td><b><c:out value="${contentFeeder.worldNews}"/></b></td>
</tr>
</cjp:personalizer>
...
Rozwiązanie wykorzystujące standardowe znaczniki JSP, jest przez wielu ekspertów [Alur2004,Crawford] uważane za bardziej "eleganckie". Związane jest to z faktem całkowitego wyeliminowania kodu Javy z głównego widoku. Taka strategia umożliwia zastosowanie podziału odpowiedzialności (ang. "separation of concern" [Sherif2000]), w którym osoba odpowiedzialna za przygotowanie szaty graficznej (np. grafik komputerowy), nie musi umieć programować a jedynie wykorzystywać elementy przygotowane przez inne osoby. Kod zamieszczony poniżej przedstawia rozwiązanie bazujące na znacznikach standardowych JSP (element jsp:include oraz @include, odpowiadają kolejno za statyczne oraz dynamiczne dołączenie zewnętrznego podwidoku).
<body>
<jsp:include page="/jsp/banner.seg" flush="true"/>
<table>
<tr>
<td>
<jsp:include page="/jsp/CompositeView/javabean/ProfilePane.jsp"
flush="true"/>
</td>
<td>
<td><%@ file="news/worldnews.html" %> </td>
</tr>
...
Strategia oparta na znacznikach własnych, jest rozszerzeniem strategii poprzedniej. Znaczniki własne są potężnym mechanizmem zarządzania zawartością i układem strony. Pomimo zwiększonego nakładu pracy programistów (proces tworzenia własnych znaczników jest złożony), jest to rozwiązanie preferowane [Alur 2004]. Zamieszczony poniżej kod przedstawia sposób wykorzystania własnych znaczników w procesie przygotowania strony.
<region:render template='/jsp/CompositeView/templates/portal.jsp'>
<region:put section='banner' content='/jsp/CompositeView/templates/banner.jsp' />
<region:put section='controlpanel' content='/templates/ProfilePane.jsp' />
<region:put section='mainpanel' content = '/templates/mainpanel.jsp' />
<region:put section='footer' content='/templates/footer.jsp' />
</region:render>
trategia bazująca na przekształceniach, to z reguły rozwiązania bazujące na XML'u oraz XSLT. Jest to rozwiązanie o największych możliwościach, ale jednocześnie najmniejszej efektywności. Widok może być wielokrotnie transformowany zanim zostanie przekazany klientowi, a każda z transformat może być niezależnie wymieniana na inną. Rozwiązanie takie jest nieocenione, kiedy z naszej aplikacji korzysta wielu klientów o różnych możliwościach (np. przeglądarka internetowa, urządzenia PDA, telefony komórkowe, itp.). Powstało wiele środowisk wspierających taką strategie np. Cocoon (http://cocoon.apache.org/). Idea działąnia przekształceń została przedstawiona na poniższym rysunku.
.jpg) Composite View strategia z wykorzystaniem przekształceń
Composite View strategia z wykorzystaniem przekształceńPodsumowanie
Wprowadzenie wzorca \textsl{Composite View} pociąga za sobą pewne konsekwencje, z których powinniśmy zdawać sobie sprawę. Oprócz pozytywnych aspektów zastosowania tego rozwiązania istnieją również słabe strony. Do plusów niewątpliwie moglibyśmy zaliczyć:
- Poprawę modularności i możliwość ponownego wykorzystania kodu.
- Możliwość dodania kontroli opartej na regułach. Do takich reguł może należeć rola użytkownika lub pewne ustawienia systemowe.
- Ułatwienie pielęgnacji kodu.
Istnieje jednak kilka negatywnych aspektów:
- Utrudnienie zarządzania kodem. Związane to jest z możliwością powstawania błędów wyświetlania podczas łączenia kilku elementów w jednym widoku.
- Zmniejszenie wydajności - związane z koniecznością dynamicznego tworzenia widoku na żądanie klienta.
Zakończenie
Dokument ten stanowi jedynie wstęp do tematyki wzorców projektowych warstwy prezentacji platformy J2EE. Pokazuje jednak jak ważną rolę mogą one odegrać w procesie projektowania aplikacji. Pozwalają zredukować koszty wytworzenia systemu, dzięki zastosowaniu sprawdzonych rozwiązań. Dzięki wzorcom możemy także efektywniej komunikować się o obrębie zespołów projektowych.
Nie należy jednak zapominać, że wzorzec projektowy stanowi jedynie szablon pewnego rozwiązania. Szablon ten następnie może być zaimplementowany za pomocą kilku strategii. Starałem się wraz z omawianiem każdego wzorca przejście od zdefiniowania problemu jaki nas dotyczy, przez wybranie ogólnego rozwiązania (wzorca projektowego), aż do jego szczegółowej implementacji będącej strategią.
Należy zdawać sobie jednak sprawę, że wykorzystywanie wzorców projektowych pomimo niezliczonej ilości korzyści generuje pewien narzut. Narzutem tym może być zwiększona liczba linii kodu, jaki należy wpisać, może być nim również zwiększony czas wykonywania się naszego programu.
Bibliografia
[ALUR2004] - D.Alur, J.Crupi, D.Malks, "Core J2EE Wzorce projektowe"
[Crawford] - W.Crawford, J.Kaplan, "J2EE Stosowanie wzorców projektowych"
[Sherif2000] - M.Y.Sherif, H.H.Ammar, "Pattern-Oriented Analysis and Design: Composing Patterns to Design Software Systems"
Bezpieczny to_param
Wykorzystując Ruby on Rails chcielibyśmy tworzyć bardziej przyjazne/opisowe adresy url. Weźmy za przykład biuletyn rynku New Connect. W biuletynie tym znajdują się linki do bieżących lub archiwalnych artykułów. Byłoby lepiej, żeby zamiast wywołania www.ncbiuletyn.pl/czytaj/1, zobaczyć www.ncbiuletyn.pl/czytaj/1-debiuty_sierpniowe.html
Aby osiągnąć taki efekt nie musimy za wiele robić wystarczy nadpisać w klasie modelu metodę to_param. Możemy to zrobić w taki sposób:
def to_param
"#{self.id}-#{self.tytul}"
end
Musimy jednak pamiętać, że nie każdy ciąg znaków będzie prawidłowym adresem url i niektóre artukuły mogą nam się po prostu przestać wyświetlać. Musimy zatem zabezpieczyć przed tym naszą aplikację i usuwać z pola niedozwolone znaki. Możemy to osiągnąć w poniższy sposób:
def to_param
"#{self.id}-#{self.tytul.gsub(/(\W)/,"_")}"
end
Dodanie counter cache do istniejącej tabeli
Dodanie counter cacha do isteniejącej tabeli (dla relacji jeden- wiele) rozpocząć powinniśmy od stworzenia migracji dodającej do tabeli (w obiekcie agregującym) dodatkowej kolumny. Załóżmy w tym przypadku, że w naszej aplikacji posiadamy tabele Miasta oraz tabelę powiaty. Obie są w relacji jeden-do-wielu.
class Miasto < ActiveRecord::Base
validates_presence_of :nazwa, :message => "jest wymagana"
belongs_to :powiat
end
class Powiat < ActiveRecord::Base
validates_presence_of :nazwa, :message => "jest wymagana"
has_many :miasta
end
Uwaga: jeżeli chcesz używać polskich nazw w modelach przeczytaj ten artykuł.
Zanim przejdziemy do modyfikacji tabel zaznaczmy w modelu, że chcemy używać kolumny counter_cache.
class Miasto < ActiveRecord::Base
validates_presence_of :nazwa, :message => "jest wymagana"
belongs_to :powiat, :counter_cache => true;
end
Następnie dodajmy migrację:
script/generate migration powiaty_add_counter_cache
W migracji wpisujemy następujący kod
add_column :powiaty, :miasta_count, :integer, :default => 0
Powiat.find(:all).each do |p|
Powiat.update_counters p.id, :miasta_count => p.miasta.length
end
W tym momencie nasza aplikacja będzie miała prawidłowo ustawione liczniki.
Counter Cache w ruby on rails dla relacji many-to-many
Rails dostarcza wiele cennych narzędzi, które w nieprawdopodobny sposób potrafią przyspieszyć proces tworzenia aplikacji. Jednym z bardzo użytecznych mechanizmów jest wsparcie dla mechanizmu counter cache.
Aby zrozumieć jak działa ten mechanizm wyobraźmy sobie, że mamy relacje typu jeden do wielu. Dla przykładu w każdym powiecie znajduje się wiele miast. 
Jeżeli chcielibyśmy w naszej aplikacji wyświetlać przy każdym powiecie informacje o liczbie miast jaka sie w nim znajduje musielibyśmy za każdym razem wywołać:
Select count(*) from miasta where powiat_id = id
Łatwo się zorientować, że jeżeli liczba miast i powiatów jest duża to takie rozwiązanie jest wysoce nieefektywne. Rozwiązaniem staje się wprowadzenie dodatkowej kolumny do tabeli powiaty zawierającą policzoną wcześniej liczbę miast. Teraz pozostaje jedynie pilnowanieaby przy każdym dodaniu lub usunięciu relacji powiat - miasto informacja w dodatkowej kolumnie została zaktualizowana.
W przypadku przedstawionej tutaj relacji sam Rails czuwa nad tym aby liczba ta pozostała prawidłowa wystarczy, że zrobimy następujące kroki:
1.Zdefiniujemy migracje:
class CreateRelacja < ActiveRecord::Migration
def self.up
create_table :miasta do |t|
t.string :nazwa, :limit => 35
t.integer :miasto_id
t.timestamps
end
create_table :powiaty do |t|
t.string :nazwa, :limit => 35
t.integer :miasta_count, :default => 0
t.timestamps
end
end
end
Uwaga: bardzo ważne jest aby kolumna miasta_count zainicjowana została domyślną wartością 0 – w przeciwnym przypadu licznik nie będzie działał (jeżeli chcesz dodać counter_cache w istniejącej tabeli zobacz tego posta (http://mstanek.blogspot.com/2008/06/dodanie-counter-cache-do-istniejcej.html)).
2.W następnym kroku należy zmodyfikować klasy modelu:
class Miasto < ActiveRecord::Base
validates_presence_of :nazwa, :message => "jest wymagana"
belongs_to :powiat,:counter_cache => true;
end
class Powiat < ActiveRecord::Base
validates_presence_of :nazwa, :message => "jest wymagana"
has_many :miasta
end
Takie rozwiązanie jest szybkie i całkowicie wspierane przez Railsa. Niestety wsparcia takiego nie otrzymujemy dla relacji wiele do wiele.
W tym momencie za model posłuży nam baza usług medycznych informacja-madyczna.pl. Występuje tam związek pomiędzy specjalizacjami a lekarzami. Jest wielu lekarzy posiadających daną specjalizację, a każdy z nich może posiadać więcej niż jedną specjalizację. Jest to ewidentnie związek wiele do wiele.

Nasz model wygląda zatem w następujący sposób:
class Lekarz < ActiveRecord::Base
has_and_belongs_to_many :specjalizacje
end
class Specjalizacja < ActiveRecord::Base
has_and_belongs_to_many :lekarze
end
Aby załóżmy zatem, że chcemy mieć informacje dotyczącą ilości lekarzy z daną specjalizacją. W kodzie informację taką można uzyskać w nastepujący sposób:
Specjalizacja.find_by_nazwa('ginekologia').lekarze.length
Niestety wyciągnięcie w ten sposób informacji dla każdej specjalizacji jest bardzo czasochłonne. Dodajmy zatem kolumnę licznika w tabeli specjalizacje, tak abyśmy mogli wyliczoną w powyższy sposób liczbę zachować. Tworzymy zatem migrację a w migracji dodajemy następujący kod:
add_column :specjalizacje, :lekarze_count, :integer, :default => 0
Specjalizacja.find(:all).each do |s|
s.lekarze_count = s.lekarze.length
s.save
end
Proszę zauważyć, że aby zachować jednolity zapis z wbudowanym mechanizmem couter_cache kolumna została nazwana w analogiczny sposób.
W tym momencie posiadamy już informację o liczności każdego związku – jest ona przechowywana w klasie Specjalizacja. Teraz pozostaje najtrudniejsza część, należy mianowicie zadbać o to, żeby w czasie dodawania bądź usuwania obiektów z relacji licznik ulegał zmianie. Należy tutaj zwrócić uwagę, że modyfikaje tego typu możemy wprowadzać po obu stronach relacji. Pokaże to na przykładzie dodania nowej specjalizacji lekarzowi, którą możemy wykonać na dwa sposoby:
lekarz = Lekarz.find_by_imie_and_nazwisko('Jan','Kowalski')
specjalizacja = Specjalizacja.find_by_nazwa('ginekologia')
1. sposób:
lekarz.specjalizacje << specjalizacja
lekarz.save
2. sposób:
specjalizacja.lekarze << lekarz
specjalizacja.save
Z dokumentacji relacji has_many dowiadujemy się, że posiada ona dwa bardzo pomocne nam modyfikatory :before_add oraz :before_remove. Pozwolą nam one na śledzenie zmian, które powinny zostać odzwierciedlone w wartości licznika. Rozszerzmy zatem naszą klasę Lekarz o śledzenie zmian i poprawę licznika:
class Lekarz < ActiveRecord::Base
has_and_belongs_to_many :specjalizacje,
:before_add => :counter_inc,
:before_remove => :counter_dec
def counter_inc(t)
counter_change(t, 1)
end
def counter_dec(t)
counter_change(t, -1)
end
private
def counter_change(object, amount)
object.lekarze_count = object.lekarze_count+amount;
object.save
end
end
A następnie klasę Specjalizacja
class Specjalizacja < ActiveRecord::Base
has_and_belongs_to_many :lekarze,
:before_add => :counter_inc,
:before_remove => :counter_dec
def counter_inc(t)
t.counter_inc(self)
end
def counter_dec(t)
t.counter_dec(self)
end
end
W tym momencie udało nam się stworzyć mechanizm counter_cache dla relacji wiele do wiele (many-to-many). Oczywiście pozostaje nam napisanie odpowiednich testów, ale to zadanie pozostawiam już czytelnikowi.
Monday, June 16, 2008
Poprawione wyrażenie regularne dla e-maila
Ponieważ wyrażenie regularne służące do weryfikacji poprawności e-maila podane w dokumentacji rubiego nie jest doskonałe (zakłada konieczność wprowadzenia e-maila) oraz umożliwia wstawienie w nim znaku '?' poniżej podaje zmodyfikowane wyrażenie nie posiadający w.w. wad:
validates_format_of :email,
:with => /(^([^@\s?]+)@((?:[-_a-z0-9]+\.)+[a-z]{2,})$)|(^$)/i,
:message => "ma błędny format (przykładowy poprawny email przyklad@domena.pl)"
Korzystając z okazji podam również wyrażenie regularne które może służyć do weryfikacji poprawności wpisanego numeru telefonu:
validates_format_of :telefon,
:with => /^[+]{0,1}[-0-9()\s]+$/,
:message => "ma błędny format (przykłady poprawnych: +48 071 123 123, 012-12-332)"
Why ActiveRecord::HasManyThroughAssociationNotFoundError: Could not find the association arrise?
Tworząc zależności wiele do wiele możemy wykorzystać przełącznik through i zapisać w danej asocjacji dodatkowe informacje np. relacja Czytelnik - Artykul, może zawierać np. ocenę wystawioną danemu artykułowi. Nie wchodząc w szczegóły jak tworzyć takie związki (na sieci znajduje się kilka dość dobrych tutoriali które łątwo wygooglować), czasami napotkać na poniższy wyjątek:
ActiveRecord::HasManyThroughAssociationNotFoundError: Could not find the association
Aby rozwiązać ten problem należy pamiętać, że klasa będąca złączeniem musi być jawnie dodana do zależności w klasach bazowych. Na przykładzie:
class Lekarz < ActiveRecord::Base
has_many :placowki, :through => :pracownicy
has_many :pracownicy
end
class Placowka < ActiveRecord::Base
has_many :lekarze, :through => :pracownicy
has_many :pracownicy
end
class Pracownik < ActiveRecord::Base
belongs_to :lekarz
belongs_to :placowka
end
Monday, June 09, 2008
LightWindow 2 i problem z flashowymi bannerami
Korzystając z doskonałego skryptu tworzącego tak zwany LightWindow (http://mysticearth.wordpress.com/2007/07/12/lightwindow-2-available/), napotkałem na dość uciążliwy problem. Sprawa polega na tym, że okno podglądu tworzone jest dynamicznie po kliknięciu na link. Zanim wyświetlony zostanie podgląd zlinkowanego zasobu biblioteka generuję animację rozwijającą w dość atrakcyjny sposób okienko. Wszystko jest dobrze, aż do momentu kiedy animacja ta nie jest wyświetlana na stronie, która zawiera flashowe dodatki. Efekt jest taki, że wszystkie flasha znajdują się nad animowaną warstwą okienka podglądu. Ostateczny wygląd jest dosyć nieciekawy.
Rozwiązań problemu jest zapewne wiele, ale ostatecznie zdecydowałem się na metodę, polegającą na tym, że wszystkie elementy flashowe przed wywołaniem okienka light window są ukrywane, a po jego wyłączeniu na nowo pokazywane.
Aby osiągnąć taki efekt należy skorzystać z dobrodziejstw jakie daje nam biblioteka Prototype (standardowo dołączana do projektu).
<script type="text/javascript">
swfobject.embedSWF("<%= url %>", "banner_<%= banner.id %>", "700", "100", "9.0.0");
</script>
<a href="http://<%= banner.url %>" style="position:relative;z-index:1;" class="banner">
<div id="banner_<%= banner.id %>" style="z-index:1;" >
<p><img src="<%= @url_for_app +banner.plik.public_filename if banner.plik %>"/></p>
</div>
</a>
Uwaga: do osadzenia obiektu Flash została użyta biblioteka SWFObject (gorąco polecam).
Następnie modyfikujemy dwie funkcji w lightwindow.js. Szukamy następującej linijki:
activate : function(e, link){
Dla ułatwienia powiem że jest to linia 252 i na samym początku dodajemy następujący wiersz:
($$('.banner').invoke('hide'));
Następnie w funkcji dekatywacji (linia 277):
deactivate : function(){
wstawiamy
($$('.banner').invoke('show'));
Dzięki takim kosmetycznym zmianom nasz problem został rozwiązany.
Przekazanie bloku kodu do metody helpera
Korzystanie z dobrodziejstwa rubiego jakim jest przekazywanie bloku kodu do metody można wykorzystywać projektując metody w klasach Helperów. Aby wykorzystać ten mechanizm należy jednak zastosować specjalną kontrukcję, którą pokrótce postaram się wyjaśnić.
Załóżmy, że projektowana przez nas witryna składa się z wielu modułów, z których każdy posiada nagłówek oraz treść. Za każdym razem te dwie rzeczy opakowywane są w serię divów z przypisanymi odpowidnimi klasami. Nasze zadanie polegać będzie na tym aby napisać metodę w klasie ApplicationHelper umożliwiającą wstawienie wspomnianego modułu w dowolnym widoku.
Zacznijmy więc od definicji metody:
def modul_tematyczny(tytul, &block)
end
Następnie w widoku umieśćmy następujące wywołanie:
<div ....> .... </div>
<% modul_tematyczny("Wstawiony modul") do %>
<ul>
<% @wiadomosci.each do |wiadomosc|%>
<li> <%= wiadomosc.temat-%> - <%= wiadomosc.updated_at %></li>
<% end %>
</ul>
<% end%>
<div ....> .... </div>
Powróćmy w do helpera i dodajmy odpowiedni kod, tak aby wszystko razem zaczęło działać:
def modul_tematyczny(tytul, &block)
blok = capture(&block)
res = <<HTML
<div class="modul">
<h1 class="tytul">#{tytul}</h1>
<div class='zawartosc'>
#{blok}
</div>
</div>
HTML
concat(res, block.binding)
end
Jak nie trudno zauważyć całą magię stanowią dwa wywołania, które wiążą blok kodu ze zmienną, a następnie zwracają wynik. Zastosowany przykład jest wysoce niedoskonały, ale daje pogląd na możliwości jakie daje nam definiowanie helperów wykorzystujących bloki kodu.
Monday, June 02, 2008
Problem z podwójnym kliknięciem w LightWindow 2
Mam przyjemność być użytkownikiem jednej z lepszych bibliotek JavaScript do generowania tak zwanych Light Box/Window http://www.stickmanlabs.com/lightwindow/. Niestety zauważyłem, że posiada ona dość nieprzyjemny mankament objawiający się podczas podwójnego kliknięcia na linku z przypisanym stylem lightwindow. Domyślnie biblioteka rozbudowuje dla takiego elementu drzewo DOM dodając mu właściwość onClick. Niestety jeżeli nastąpi podwójne kliknięcie ramka zwiększa swoją szerokość dwa razy, co w niektórych przypadkach powoduje że staje sie szersza niż okno przeglądarki. Bezpośrednia ingerencja w bibliotekę nie jest trywialna jednak prosty trick zastosowany (niestety na każdym łączu ze stylem lightwindow) pozwala rozwiązać problem. Wystarczy dopisać:
ondblclick="return false;"
Friday, March 28, 2008
Rails a upload plików z klasą polimorficzną (Attachment_fu)
Polecam zainstalowanie plug-inu Attachment_fu
script/plugin install http://svn.techno-weenie.net/projects/plugins/attachment_fu
Następnie tworzymy model np. File /lub plik - tworząc odpowiednie inflections/, czyli
scrip/generate model Plik
w stworzona migracja powinna wyglądać następująco:
class CreatePliki < ActiveRecord::Migration
def self.up
create_table :pliki do |t|
t.column :filename, :string
t.column :size, :integer
t.column :content_type, :string
t.column :thumbnail, :string
t.column :parent_id, :integer
t.column :height, :integer
t.column :width, :integer
# Obsługa polimorfizmu
t.column :zasob_id, :integer
t.column :zasob_type, :string
t.timestamps
end
end
def self.down
drop_table :pliki
end
end
A nasz plik modelu powinien zawierać następujący wpis:
class Plik < ActiveRecord::Base
belongs_to :zasob, :polymorphic => true # Polimorfizm
has_attachment :content_type => :image,
:storage => :file_system,
:max_size => 2.megabytes,
:resize_to => '300x300>',
:size => 0..2.megabyte,
:thumbnails => {
:small => '50x50>',
:medium => '100x100>',
:big => '200x200>'
},
:processor => :MiniMagick;
validates_as_attachment
end
Zdefiniowane zostały tutaj opcje zapisu zdjęcia uwzględniające tworzenie miniaturek za pomocą biblioteki MiniMagic. Aby ją zainstalować powinniśmy wpisać w konsoli:
sudo gem install mini_magick
Teraz wiążemy nasze zdjęcie z jakąś istniejącą klasą modelu. W naszym przypadku niech będzie nią klasa produkt:
class Produkt < ActiveRecord::Base
has_and_belongs_to_many :kategorie
belongs_to :producent
has_one :plik, :as => :zasob #,:class_name => 'Plik'
validates_presence_of :nazwa, :message => "nie może być pusta"
validates_presence_of :cena, :message => "nie może być pusta"
validates_length_of :nazwa, :minimum=>2, :message=> "musi składać się przynajmniej z dwóch znaków"
validates_numericality_of :cena, :greater_than_or_equal_to => 0, :message => "nie może być ujemna"
end
W następnej kolejności musimy uzupełnić widoki o możliwość dodawania oraz wyświetlania naszego obrazka. W formularzu dla akcji new oraz edit powinniśmy mieć następujący wpis
<% form_for(@produkt, :html => { :multipart => true }) do |f| %>
....
<%= file_field :plik, :uploaded_data %>
....
<% end %>
Musimy również uzupełnić nasz kotroler o zapis załączonego pliku. W akcji update oraz create należy dodać następujący kod:
unless params[:plik].blank?
@produkt.plik = Plik.new(params[:plik])
p.save
end
Wyświetlić nasz załączony plik możemy w następujący sposób:
<%= image_tag(@produkt.plik.public_filename(:big)) if @produkt.plik%>
gdzie :big to nazwa thumbnailsa podana w modelu. Jeżeli nie podamy tego parametru wyświetlony będzie oryginalny obrazek.
Przedstawiłem podstawowe kroki niezbędne do dodania możliwości przechowywania plików związanych z naszymi klasami modelu. Po więcej informacji odsyłam do:
http://www.railslodge.com/plugins/108-attachment-fu
http://clarkware.com/cgi/blosxom/2007/02/24
http://blog.defv.be/2007/12/19/attachment_fu-with-polymorphic-association
http://khamsouk.souvanlasy.com/2007/5/1/ajax-file-uploads-in-rails-using-attachment_fu-and-responds_to_parent
Ruby MySQL i UTF8
Najprostszy sposób na ustawienie MySQL do pracy w UTF-8, to modyfikacja pliku my.cnf. Plik ten znajduje się w katalogu /etc/mysql/my.cnf. W pliku tym w sekcji zmodyfikować 2 sekcje [mysqld] oraz [client]:
[mysqld]
character-set-server = UTF8
default-character-set = UTF8
collation_server = utf8_polish_ci
[client]
default-character-set=utf8
Następnie aby ruby poprawnie radził sobie z zapisem do tak stworzonej bazy należy zmodyfikować plik environment.rb znajdujący się w podkatalogu /config/. Do pliku tego dodajemy następujący wpis:
config.action_controller.default_charset = "utf-8"
Jeżeli tworzyliśmy projekt za pomocą rails -d mysql nazwa_projektu automatycznie w pliku konfigurującym połączenie z baza danych powinniśmy otrzymać podobny zestaw wpisów:
development:
adapter: mysql
encoding: utf8
database: projekt_development
username: root
password:
socket: /var/run/mysqld/mysqld.sock
/Podobmne wpisy będą wygenerowane również dla środowiska test oraz production/
Uwaga: jeżeli pomimo wprowadzenia zmian opisanych powyżej nasza baza danych dalej błędnie obsługuje polskie znaki dialektyczne, najprostszym sposobem aby sobie z tym poradzić jest usunąć wszystkie tabele i stworzyć je na nowo /rake db:create:all oraz rake migrate/.
Thursday, March 20, 2008
Ruby on Rails - polskie komunikaty błędów przy walidacji
W przypadku używania walidatorów dla stron polskojęzycznych pojawia się problem z niezręcznymi angielskimi komunikatami błędów. Aby spolonizować w prosty sposób nasze komunikaty wystarczy dokonać tylko kilku modyfikacji.
Załóżmy, że w naszym modelu mamy następującą klasę:
class Produkt < ActiveRecord::Base
#pola => Nazwa, Cena,
end
Spolonizowana walidacja mogłaby wyglądać w takim przypadku następująco:
class Produkt validates_presence_of :nazwa, :message => "nie może być pusta"
validates_presence_of :cena, :message => "nie może być pusta"
validates_length_of :nazwa, :minimum=>2, :message=> "musi składać się przynajmniej z dwóch znaków"
validates_numericality_of :cena, :greater_than_or_equal_to => 0, :message => "nie może być ujemna"
end
W tym momencie część pracy już za nami. Metoda
<%= error_message_for :produkt -%>
działa już prawie tak jak byśmy chcieli. Pozostaje usunięcie nagłówka i wstępnego komunikatu, który w dalszym ciągu pojawia się w języku angielskim. Rozwiązanie jest dość trywialne (oczywiście jeżeli wiadomo gdzie szukać). Poprawiona wersja metody wygląda więc tak:
<%= error_messages_for :produkt, :header_message => "Błąd !", :message => "Lista błędów:"%>
Polecam również lekturę:
http://www.rubyonrails.pl/forum/p3572-2007-10-22-00:50:44
Wednesday, March 19, 2008
Rails paginacja z polskimi nazwami w osobnej metodzie helpera
Aby nie powielać wpisywanego kodu paginatora (will_paginate) parametryzując go o polskie napisy dla przycisków 'next' i 'previous' możemy stworzyć oddzielną metodę w module ApplicationHelper.
def paginacja(kolekcja)
will_paginate kolekcja,
:inner_window => 10,
:outer_window => 10,
:prev_label => "« Poprzednie",
:next_label => "Następne »"
end
Następnie w widoku możemy wywołać tą metodę w następujący sposób.
<%= paginacja @produkty %>
Oczywiście aby działała cała paginacja należy zainstalować plugin will_paginate oraz przygotować odpowiednio kolekcję w kontrolerze:
@produkty = Produkt.paginate(:order => 'nazwa DESC',
#:conditions => ["active = ?", 1]
:per_page => 10,
:page => params[:page])
Jeżeli przeczytałeś ten artykuł do końca to prawdopodobnie zainteresuje Ciebie również paginacja w Rails 2.1